Prometheus is a time series database and monitoring tool that works by polling metrics endpoints and scraping and processing the data exposed by these endpoints. It allows you to query this data using PromQL, a time series data query language. Prometheus will be deployed into the cluster as a StatefulSet with 2 replicas that uses Persistent Volumes with DigitalOcean Block Storage. In addition, a preconfigured set of Prometheus Alerts, Rules, and Jobs will be stored as a ConfigMap. To learn more about these, skip ahead to the Prometheus section of Configuring the Monitoring Stack.

Prometheus is a tool for monitoring and alerting, especially focused on time series data. It is the backend that collects and stores the data, and has a minimal frontend where you can run one-off queries, see graphs, etc. You can't save graphs or create dashboards - that's where Grafana comes in.Prometheus polls various "targets" to get metrics at specified frequencies.

The targets are configured in prometheus.yml which is baked into our prometheus docker image. Running cluster monitoring with persistent storage means that your metrics are stored to apersistent volume and can survive a pod being restarted or recreated. This is ideal if you require your metrics or alerting data to be guarded from data loss. For production environments, it is highly recommended to configure persistent storage using block storage technology. Make Grafana your partner if you have data expressed as numbers over time.

Grafana is best used to represent time-series data (i.e. numeric data points sequenced over intervals of time) and it can generate colorful visualizations out of them. These data can be represented in real time over various types of panels and dashboards letting the users monitor different KPIs effortlessly. Grafana is also open-source, free and easy to manage/set up. With newer containerized technologies like docker, pre-saved images and configs could be set up in a couple of minutes with only a few commands. We will install cAdvisor agents in each nodes to collect host and container metrics. We will use Grafana to setup dashboards for this metrics.

All these tools are open-source and can be deployed as a container. Docker Compose is a powerful tool to use when dealing with deployments of Docker applications with multiple containers. It gives users the ability to explicitly define the specifications needed for each service in their application, and concisely start all the services together with a single command. Docker volumes are the mechanism by which Docker persists data. They are easy to back up, migrate, and share among different containers.

Additionally, they do not increase the size of the container using them, but instead exist separate to the run state of the container. That means that if a container is stopped or deleted, a volume will still be running with the data it has been populated with. Volumes are directories that live outside Docker's Union File System on the host machine but within the Docker area of the host. This uses the influxdb image and for persistent storage, we are creating a volume named influx that is mounted to the /var/lib/influxdb folder in the container. In the deploy key, we are saying that we need one copy of InfluxDB which we will place in the manager. Since we are using docker engine in the manager, we can execute commands to this container from here itself.

As both the other services needs influxDB to run, we will add a depends_on key to other services with influx in it. It supports a SQL like query language to query for data. The tags let us filter data for a specific host and even a spefic container. We don't have to manually configure data sources and dashboards for Grafana. Thanks to the Grafana provisioning feature, we can use configuration files to set up everything before running the application for the first time.

Prometheus' built-in remote write capability forwards metrics from your existing Prometheus servers to the Telemetry Data Platform. Once your metrics are in the Telemetry Data Platform, you instantly benefit from 13 months of retention and on-demand scalability. With all of your telemetry data in one place, you can build dashboards that combine and group data from across your entire software stack. 1You may wish to include our Couchbase ServiceMonitor in the monitoring namespace along with the other ServiceMonitors included in the provided kube-prometheus manifests. Please see Configure Prometheus Metrics Collection on how to create said Secret.5Pass in the value of the key field in the secret data. Antoine Solnichkin Antoine is an experienced software engineer and aspiring enterprise architect in Luxembourg.

On a daily basis, he is involved in architecting, developing and maintaining large industrial projects with complex needs. Used by many successful companies worldwide, InfluxDB is often deployed in distributed and often multicloud. Docker can serve as a good fit for many organizations as a virtualization environment that provides an easy way to create, manage and delete containers on the fly.

If you are trying to build reliable monitoring architectures, one solution would be to install InfluxDB on Docker and to manage it with Kubernetes. When using Docker Compose, it is relevant to understand Docker volumes and how they are used to persist configurations and data. Persistence is important, because it allows data to continue to exist after the machine or service that created them is terminated. It also allows that information to be transferred to another host computer intact. We will use Docker volumes to create a pseudo-persistence of configuration and possibly data . It is important to note that for backing up stateful services such as a database, this is not the proper method.

For our example, we will be persisting a Grafana configuration file that will visualize data from an InfluxDB database. This will start the services in the stack which is named monitor. This might take some time the first time as the nodes have to download the images.

Also, you need to create the database named cadvisor in InfluxDB to store the metrics. CAdvisor collects the metric from the host and docker containers. It is deployed as a docker image with shared volumes to docker socket and root file system of the host. CAdvisor pushed these metrics to a bunch of time-series database including InfluxDB, Prometheus, etc. It even has a web UI that shows graphs of the metrics collected.
To conclude, Grafana and Splunk are completely two different tools serving completely different purposes. Grafana would be great to visualize KPIs whereas Splunk would be great to search and query data among large volumes of logs. If you think Grafana is the right product for you, sign up for a demo with MetricFireor do a the free trial, and learn more. Before you begin, it is important to review a few details about networking. By default, newly created containers run on the bridge network stack.

In addition, after you install InfluxDB, it will be exposed to useful ports on your network stack. Later, you can also bind Telegraf to it, but Telegraf does not have to expose any ports to your current host stack. We will eventually run InfluxDB on the default bridge network, and have Telegraf running in the same stack as InfluxDB. In addition, we will add Grafana to our bridge network in order to visualize metrics gathered by Telegraf. As mentioned above, we will provide more details about setting up Telegraph in Part 2 of this series.

OpenShift Container Platform ships with a pre-configured and self-updating monitoring stack that is based on the Prometheus open source project and its wider eco-system. It provides monitoring of cluster components and ships with a set of alerts to immediately notify the cluster administrator about any occurring problems and a set of Grafana dashboards. CAdvisor service has much more configuration required than the other services. We intend to put one agent in each node of the swarm and this container will collect all metrics from the node and the containers running in it.

When cAdvisor send metrics to InfluxDB, it send it with a tag machine that contains the hostname of cAdvisor container. We need to match it with the hostname of the node running it. We have named the containers with the ID of the node running it so that we know where the metric is coming from. The Kubernetes dashboard currently supports resource metrics integration via Heapster. A word of caution before we move on though; Heapster is currently being deprecated in favor of metrics server.

Support for metrics api is being actively worked on by the Kubernetes community as part of the v2 dashboard launch. Any production-ready deployment requires you to configure a persistent storage interface that will be able to maintain historical metrics data and survive pod restarts. The output of promtool tsdb create-blocks-from rules command is a directory that contains blocks with the historical rule data for all rules in the recording rule files. Once moved, the new blocks will merge with existing blocks when the next compaction runs. Grafana is a data visualization and analytics tool that allows you to build dashboards and graphs for your metrics data.

Grafana will be installed as a StatefulSet with one replica. In addition, a preconfigured set of Dashboards generated by kubernetes-mixin will be stored as a ConfigMap. The Grafana monitoring extension requires a default persistent storage class.

You can either create a cluster with a default persistent storage class, or specify one in the Grafana configuration file when deploying the extension. See Review Persistent Storage Requirements for TKG Extensions. By default, use the username admin and password admin to login to grafana. The first thing to do in grafana is to add InfluxDB as the datasource. In the home page, there must be a Create your first data source link, click that.

If the link is not visible, you can select Data Sources from menu and choosing Add data source from there. We will be creating 3 local VMs to form the swarm using the Virtualbox plugin of docker-machine. For this, you need to have Virtualbox installed in the system.

You may also deploy the nodes in cloud services using different plugins. The steps after creating in the VMs are same for all the plugins. We will use the Docker Swarm Mode to build the cluster and deploy these services as a stack. Once we deploy this stack in a swarm, any new nodes joining the swarm will be automatically monitored. Opening this url will take us to the account authentication page for the Kubernetes dashboard.

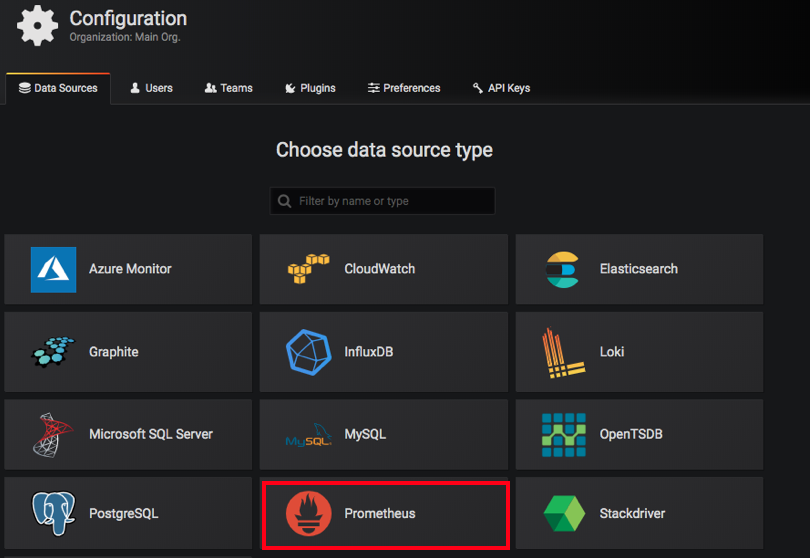
To get access to the dashboard, we need to authenticate our account. As mentioned earlier, running the Kubectl command does create a default service account as well as a role and role binding for the dashboard. You can access the dashboard using the token from the default service account. However to cover the authentication process in more detail let's create a service account from scratch and also attach a larger set of permissions to it. Select Add data source, and select Prometheus as the time series database. Grafana Reporting is your hammer for breaking down the information silos created by Grafana.

A complete 'Kubernertes monitoring with Prometheus' stack is comprised of much more than Prometheus servers that collect metrics by scraping endpoints. These dashboards are generated by kubernetes-mixin, an open-source project that allows you to create a standardized set of cluster monitoring Grafana dashboards and Prometheus alerts. To learn more, consult the kubernetes-mixin GitHub repo. A monitoring system usually consists of a time-series database that houses metric data and a visualization layer.

In addition, an alerting layer creates and manages alerts, handing them off to integrations and external services as necessary. Finally, one or more components generate or expose the metric data that will be stored, visualized, and processed for alerts by the stack. InfluxData delivers a complete open-source platform built specifically for metrics, events, and other time- based data — a modern time-series platform. The admin password must be specified before the first reconfigure after installation.

After this, the admin_password setting doesn't have any effect, and you'll have to reset the password manually. Also, to access the admin account, you have to enable login using username and password. In the github repository, I have added the file dashboard.json, that can be imported to Grafana. This will provide a dashboard that monitors the systems and the containers running in the swarm. We will import the dashboard now and talk about it in the next section. From the menu, hover over Dashboards and select Import Option.
Click the Upload .json file button and choose the dashboard.json file. Select the data source and click the Import button to import this dashboard. CAdvisor need the volumes mentioned in the file to collect the metrics from the host and docker system. This will ensure that exactly one instance of cadvisor service will be run in each node of the swarm. With the version 3 of docker-compose file, we can define the entire stack with the deployment strategy with one file and deploy it with one command. The main difference between version 2 and 3 of docker-compose file is the introduction of the deploy parameter for each service.

This parameter will define where and how you want the containers to be deployed. The docker-compose file for the monitoring file is given below. Grafana is a popular graphing tool that lets you build dashboards with data from Graphite, Elasticsearch, OpenTSDB, Prometheus and, of course, InfluxDB. From version 4 of grafana, you can also setup alerts based on query conditions.

We will setup dashboard that can be drilled down to specific host and service. One alternative to resource monitoring via the Kubernetes dashboard is to setup an alternative resource monitoring pipeline using tools like Prometheus and Grafana. Prometheus and Grafana together give us access to more in-depth resource metrics for clusters as well as individual Kubernetes objects.

These are however, still restricted to native Kubernetes objects. In this blog post we took a deep dive into the Kubernetes dashboard. We started by looking at the functionality provided by the dashboard and then covered the topics of installation, deployment and authentication. Finally we outlined the process of integrating resource metrics into the dashboard by installing Heapster. The token authentication method requires us to create a new service account for the Kubernetes dashboard. We will bind this service account to the cluster-admin role, which will give us access to all Kubernetes resources on the dashboard.
We can then use the bearer token for the service account to log in to the dashboard. To create an ephemeral Grafana deployment, apply the Managed Service for Prometheus grafana.yaml manifest to your cluster, and port-forward the grafana service to your local machine. The following example forwards the service to port 3000.



No comments:
Post a Comment
Note: Only a member of this blog may post a comment.